56.3 Bayes Revision Grid
The grid approach to Bayes' revision also revises the known probabilities to create the probabilities needed for the model. However, it differs in two significant ways:
-
It supports any m-by-n sized grid.
-
It generates the tree structure rather than referring to an existing tree structure.
To use the grid Bayes' revision, you should first obtain numeric values for the likelihood probabilities associated with the test and the a priori probabilities for the hypotheses. Then, use the grid revision wizard to create the model's structure and probabilities.
This section will examine the contents of an oil well and a test for seismic soundings. We will assume that we have knowledge about wells in a target area based on prior success in the immediate region. Based on that knowledge, we estimate the likelihood that the well has no oil, some oil or lots of oil as shown below.
| Condition | Probability |
|---|---|
|
No Oil |
5/10 (50%) |
|
Some Oil |
3/10 (30%) |
|
Lots of Oil |
2/10 (20%) |
Based on prior experience, a table is constructed showing what we can expect for test results (test neg, test pos moderate, or test pos high) based on a well’s actual state (no oil, some oil, or lots of oil) as shown below.
| Condition | Test Low | Test Med | Test High |
Total |
|---|---|---|---|---|
|
Given No Oil |
0.6 |
0.3 |
0.1 |
1.0 |
|
Given Some Oil |
0.3 |
0.4 |
0.3 |
1.0 |
|
Given Lots of Oil |
0.1 |
0.4 |
0.5 |
1.0 |
Note: This example uses the default 3x3 grid. Please note that the grid does not need to be symmetrical.
The starting point for your Bayes' revision is a chance node with no branches. The subtree generated by the process can then be copied or moved later as needed. The Oil tutorial examples model, BayesGrid-start.trex, is a quick starting point for working with the grid Bayes' revision.
To start the grid Bayes' revision:
-
Open the BayesGrid-start.trex model.
-
Select a chance node with no branches.
-
Choose Subtree > Bayes' Revision > M by N grid from the menu.
The Wizard then opens.
Note the two spinners at the top that can be used to change the shape of the grid.
The wizard provides entry fields to the left for the condition descriptions (for node labels), for condition short names (for variable names) and variable definitions (for values). It also provides entry fields for test results (for node labels), for test result short names (for variable names) and given conditions (for values).
Based on the information provided earlier, the grid could be filled out as seen below. The "Show Bayes Grid" link has been clicked to show all the Bayes' revision calculated values.
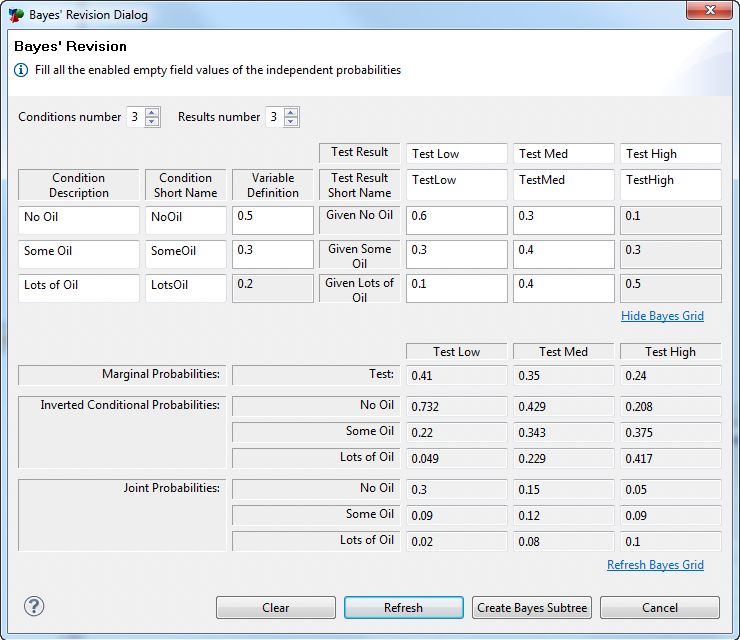
Then click Create Bayes Subtree to create the subtree with all independent, conditional and calculated variables created and defined.
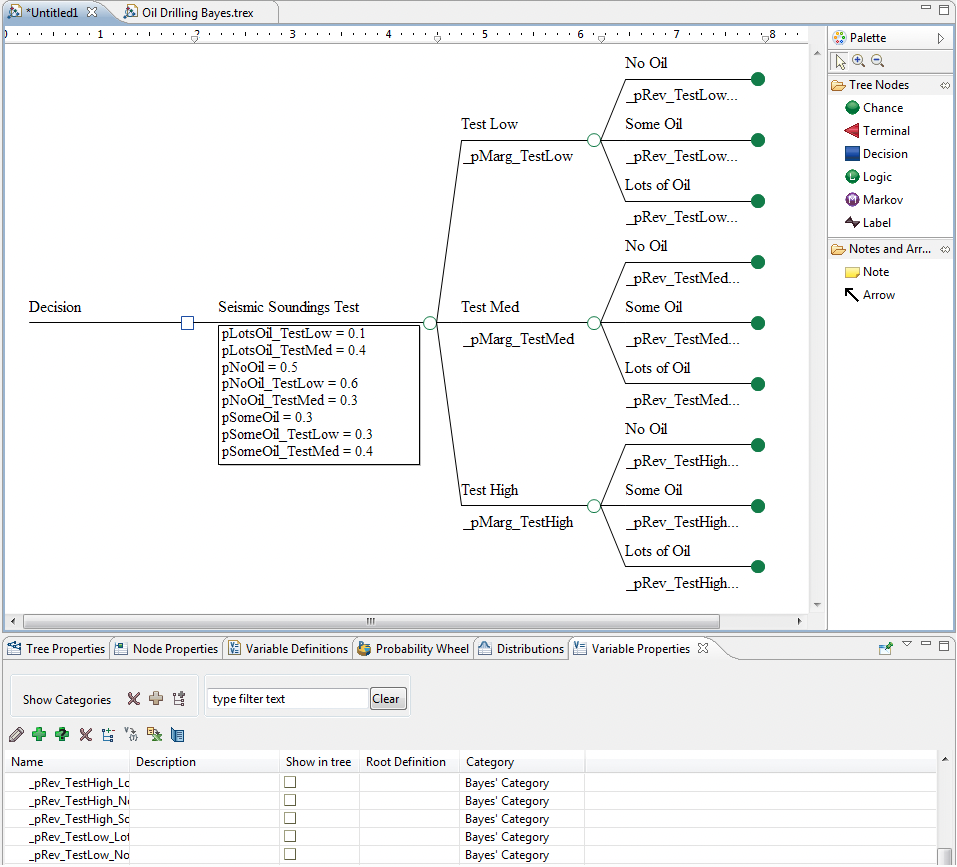
Note the following elements of the subtree that is created.
-
The tree structure is built automatically based on the M by N grid.
-
The node labels are populated based on the Condition Description and Test Result labels entered in the grid.
-
The independent variables are named based the short names entered for the condition and test results and are defined based on values in the grid.
-
The revised probability variables are named starting with an underscore and are not "shown in tree." They are defined using Bayes' revision theorem.
The Oil tutorial example, BayesGrid-end.trex, is a tree after the revision with the end nodes changed to terminal nodes to display the path probabilities, as shown below while rolled back.
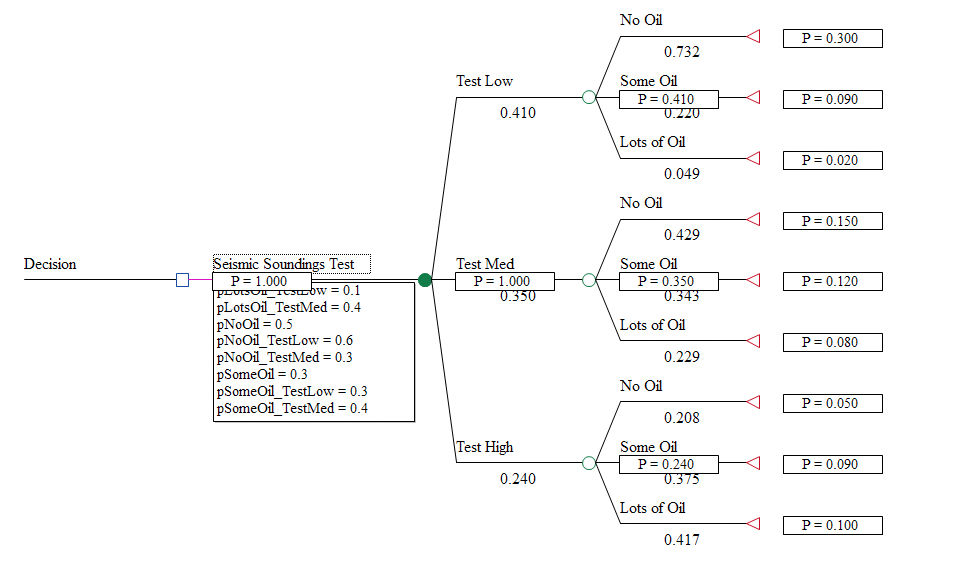
Note that the path probabilities, conditional probabilities and test result probabilities match the values presented in the grid.
The names and values entered in the last Bayes grid are stored with the model. This allows you to create another Bayes subtree using the same data. The Oil tutorial examples model BayesGrid-start-populated.trex is pre-populated with the Bayes grid data described above.
